|
Video Object Segmentation (VOS) is crucial for several applications, from video editing to video data generation.
Training a VOS model requires an abundance of manually labeled training videos.
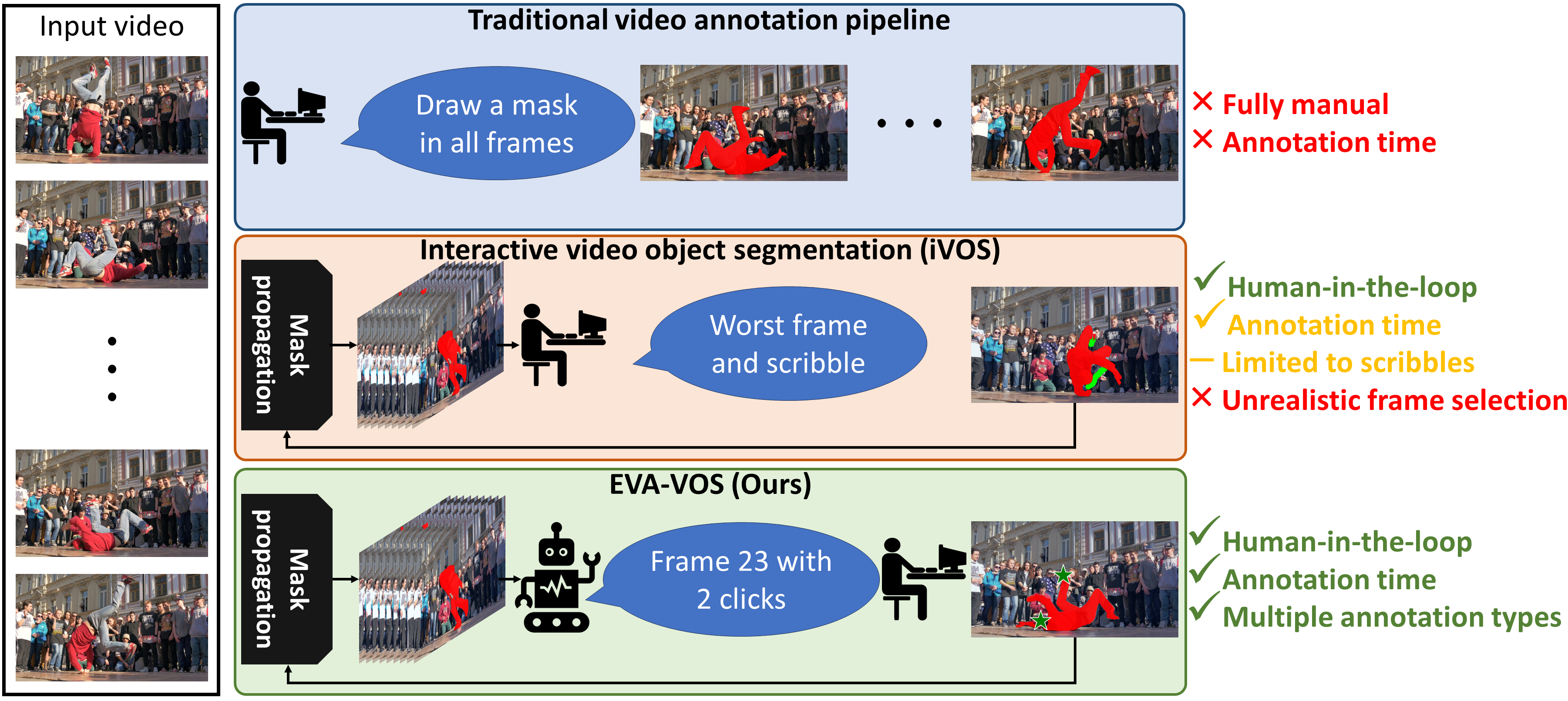
The de-facto traditional way of annotating objects requires humans to draw detailed segmentation masks on the target objects at each video frame.
This annotation process, however, is tedious and time-consuming. To reduce this annotation cost, in this paper, we propose EVA-VOS,
a human-in-the-loop annotation framework for video object segmentation. Unlike the traditional approach, we introduce an agent that predicts iteratively
both which frame ("What") to annotate and which annotation type ("How") to use.
Then, the annotator annotates only the selected frame that is used to update a VOS module, leading to significant gains in annotation time.
We conduct experiments on the MOSE and the DAVIS datasets and we show that:
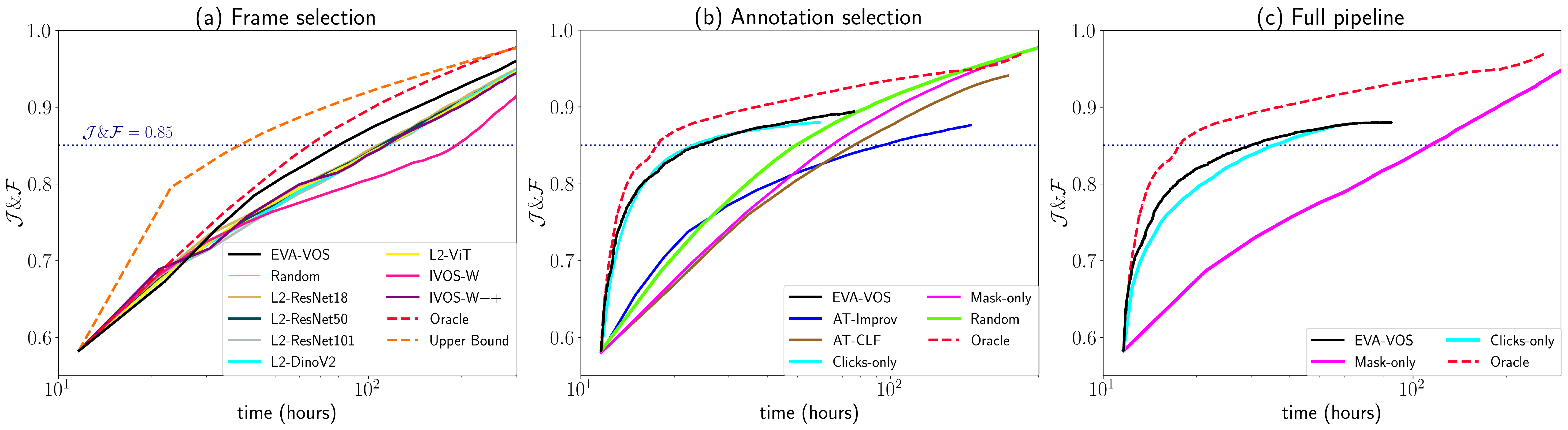
(a) EVA-VOS leads to masks with accuracy close to the human agreement 3.5x faster than the standard way of annotating videos;
(b) our frame selection achieves state-of-the-art performance;
(c) EVA-VOS yields significant performance gains in terms of annotation time compared to all other methods and baselines.
|